These days, most educational data are conceptualized as having a nested or hierarchical structure. We frequently use test and questionnaire data for students nested within classrooms and/or schools, teachers grouped by schools, or schools contained within networks or community areas. Analysis taking into consideration the nested structure of the data enables us to partition the variance in the data to that which is between groups and the variance in the data that is between individuals within groups. Failure to partition the variance (for example, treating the between-group variance as between-individual variance) is likely to produce inferences that may not be accurate. Furthermore, using data with known measurement error enables us to separate error variance from real variance in the observations.
Any type of data can be used in hierarchical models, but Rasch measures have a particular advantage over other types of data when analyzed with this method because we can adjust for individual differences in precision. Rasch measures used at level one of a hierarchical linear model are the observed data, which contain varying amounts of measurement error. This situation results in heterogeneous variance, a possible violation of one of the basic assumptions of linear models. In equation format, the level-one relationship can be stated as:
Yij = β0ij + εij
Where, Yij is the outcome for individual i in group j and
εij ~ N(0, σij²)
The error term here is not homogeneous due to the differing amounts of measurement error in the Y's. We can remove the heteroscedasticity by reweighting the measures by their inverse standard errors, or precision. So if σ^ij is the standard error of the measure Yij, we divide through by the standard error:
Y*ij = Yij * (1 / σ^ij)
Instead of the intercept we include (1 / σ^ij) so
Y*ij = β0ij(1 / σ^ij) + ε*ij
Where,
ε*ij ~ N(0,1)
Then β0ij becomes the outcome at level two, and can be described as "the latent measure for individual i in group j adjusted for measurement error" (Raudenbush and Bryk, 2002, pp. 354-355).
This method has the immediate advantage of separating out the measurement error from the individual level error. If one were to model the outcome without the reweighting the error term would contain both the residual variation and the measurement error. In a multi-level analysis, where we are concerned about partitioning the variance into between-individuals and between-groups components, the ability to remove the error variance improves our ability to get accurate estimates of the sizes of the variances.
In addition, we can include more than one outcome, similar to multivariate regression where we can take advantage of the covariance in the outcomes to improve the prediction. Another advantage of this technique in the hierarchical context is the ability to accurately estimate group-level covariances. Multiple outcomes are included on the left side of the equation in level one, with separate indicators for each of the outcomes on the right side of the equation. So, if the outcomes are Y1ij and Y2ij with corresponding standard errors σ^1ij and σ^2ij the equation becomes
(1/σ^kij)Ykij = β1ij(D1/σ^1ij) + β2ij(D2/σ^2ij) + (1/σ^kij)εij
Where,
Dk, k = {1,2} is 1 if the outcome is Yk, 0 otherwise.
The outcomes are permitted to vary randomly at the group level, having variances and covariances described by the symmetrical matrix
| t11 t12 |
| t21 t11 |
with t21 giving the covariance between the two outcomes at the group level.
Weighting by the precision and treating the observations as containing differing amounts of information will probably make the estimation more efficient, and affect the sizes of the variances (both absolute and relative) and covariances. The estimation of the fixed effects is relatively robust and will probably not be affected much by the precision weighting.
In the following example, we are analyzing two survey measures, trte (Teacher-Teacher Trust) and infl (Teacher Influence). In creating the files to be analyzed in HLM, the reweighting by precision must be done externally to the program. In SAS the following lines will do the trick:
if rsinfl > 0 then do;
inflwgt = 1/rsinfl;
trtewgt = 0;
meas = infl/ rsinfl;
output;
end;
if rstrte > 0 then do;
inflwgt = 0;
trtewgt = 1 / rstrte;
meas = trte / rstrte;
output;
end;
The two measures are infl and trte. Their fit inflated standard errors¹ are rsinfl and rstrte, respectively. The equation for this model is
MEASijk = γ100*INFLWGTijk + γ200*TRTEWGTijk+ r0jk *INFLWGTijk+ r1jk *TRTEWGTijk+ u10k *INFLWGTijk + u20k *TRTEWGTijk
In addition, in the HLM command file you have to include this statement:
FIXSIGMA2:1.00
or you will get an error message stating that there are not enough degrees of freedom available to estimate the level-1 variance.
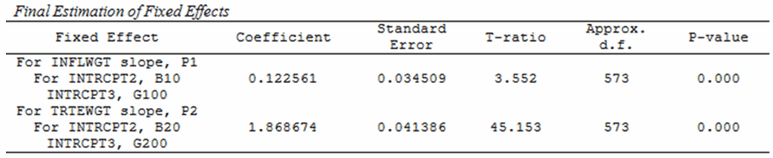
The results for the fixed effects are:
The fixed-effect estimates for infl and trte from the model without a measurement model at level one are 0.1246 and 2.0518, respectively. In general, the fixed-effect estimates are quite robust and will not be substantially affected by the addition of the measurement model. The random effects are a different story. Here is the level-3 variance-covariance matrix from the model with the measurement model at level one.
| tau(beta) | |||
| INFLWGT | INTRCPT2,B10 | 0.57039 | 0.39288 |
| TRTEWGT | INTRCPT2,B20 | 0.39288 | 0.72401 |
Here is the corresponding matrix from the model without a measurement model:
| tau | ||
| INFLIND,B1 | 0.75137 | 0.59118 |
| TRTEIND,B2 | 0.59118 | 0.93246 |
The differences are quite substantial. As you would expect, adjusting for the measurement error in the observations reduces the size of the group-level variances. Moreover, the intra-class correlation for the model with the measurement model is 0.32 and 0.19, for infl and trte, respectively. This indicates that 32 percent of the variance in infl is between schools, and the remainder is within schools, among teachers. The corresponding ICCs for the model without the measurement model are 0.17 and 0.20. However, which of these estimates is closer to the truth is an open question. Surely adjusting for different amounts of information in the observations will result in more efficient estimation. This is analogous to using GLS instead of OLS when the assumption of homogeneous variance does not hold. So, in theory, we can say that if you know the amount of error in each of your measurements you might as well take advantage of this knowledge in your analyses. But in practical terms, exactly how much your estimates will differ is not clear. I am presently working on a simulation study that will determine the concrete effects on the fixed and random effect estimates of the addition of a measurement model at level one of the HLM.
Reference
Raudenbush, S.W. and Bryk, A.S. (2002). Hierarchical Linear Models (Second Edition). Thousand Oaks: Sage Publications.
1The fit inflated standard error is rse = se * (max(1,inmnsq,outmnsq))1/2 where se is the model standard error. Sometimes we include 1/inmnsq and 1/outmnsq inside the max() but especially with measures constructed from survey data where respondents may skip any items they do not feel like answering, there can be tremendous overfit, which overweights the inflated standard errors.
Stuart Luppescu
University of Chicago Consortium on Chicago School Research
Using Rasch Measures in a Multi-level Context. Stuart Luppescu … Rasch Measurement Transactions, 2013, 27:2 p. 1413-4
| Forum | Rasch Measurement Forum to discuss any Rasch-related topic |
Go to Top of Page
Go to index of all Rasch Measurement Transactions
AERA members: Join the Rasch Measurement SIG and receive the printed version of RMT
Some back issues of RMT are available as bound volumes
Subscribe to Journal of Applied Measurement
Go to Institute for Objective Measurement Home Page. The Rasch Measurement SIG (AERA) thanks the Institute for Objective Measurement for inviting the publication of Rasch Measurement Transactions on the Institute's website, www.rasch.org.
| Coming Rasch-related Events | |
|---|---|
| May. 15 - June 12, 2026, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
| June 19 - July 25, 2026, Fri.-Sat. | On-line workshop: Rasch Measurement - Further Topics (E. Smith, Winsteps), www.statistics.com |
| Aug. 31 - Sept 2 2026, Mon.-Wed. | In person: IMEKO TC1 Metrology Education and Training symposium, Klagenfurt, Austria www.photomet-edumet2026.com. Submissions by April 20 |
| Aug. 30 - Sept. 3, 2027, Mon.-Fri. | In Person: 2027 IMEKO World Congress (TC1, Tc7, TC13, TC18, TC26), Rimini, Italy imeko2027.org |
The URL of this page is www.rasch.org/rmt/rmt272g.htm
Website: www.rasch.org/rmt/contents.htm