Extreme Raw Scores are Biased against Measures
After language, our greatest invention is numbers. Numbers make measures and maps and so enable us to figure out where we are, what we have and how much it's worth. Science is impossible without an evolving network of stable measures. The history of measurement, however, does not begin in mathematics or even in science but in trade and construction. Long before science emerged as a profession, the commercial, architectural, political and even moral necessities for abstract, exchangeable units of unchanging value were well recognized.
We begin by recalling two dramatic turning points in political history which remind us of the antiquity and moral force of our need for stable measures. Next we review the psychometric and mathematical histories of measurement, show how the obstacles to inference shape our measurement practice and summarize Georg Rasch's contributions to fundamental measurement. Finally we review some mistakes that the history of measurement has taught us to stop making.
A weight of seven was a tenet of faith among seventh century Muslims. Muslim
leaders were censured for using less "righteous" standards (Sears, 1997). Caliph
'Umar b. 'Abd al-'Aziz ruled that:
The people of al-Kufa have been struck with ... wicked practices set upon them by evil tax collectors. The more righteous law is justice and good conduct...I order you to take in taxes only the weight of seven. (Damascus, 723)
The Magna Carta of John, King of England, requires that:
There shall be one measure of wine throughout Our kingdom, and one of ale, and one measure of corn, to wit, the London quarter, and one breadth of cloth,..., to wit, two ells within the selvages. As with measures so shall it be with weights. (Runnymede, 1215)
These events remind us that commerce and politics are the source of stable units for length, area, volume and weight. It was the development of the steam engine which led to our modern measures of temperature and pressure. The success of all science stands on these commercial and engineering achievements. Although the mathematics of measurement did not initiate these practices, we will find that it is the mathematics of measurement which provide the ultimate foundation for practice and the final logic by which useful measurement evolves and thrives.
Mathematics
The concrete measures which help us make life better are so familiar that we seldom think about "how" or "why" they work. A mathematical history of measurement, however, takes us behind practice to the theoretical requirements which make the practical success of measurement possible.
1. Measures are always inferences,
2. Obtained by stochastic approximations,
3. Of one dimensional quantities,
4. Counted in abstract units, the fixed sizes of which are
5. Unaffected by extraneous factors.
As we work through the anatomy of inference and bring out the mathematical discoveries that make inference possible, we will see that, to meet the above requirements, measurement must be an inference of values for infinitely divisible parameters which are set to define the transition odds between observable increments of a promising theoretical variable. (Feller, 1950, p.271-272) We will also see what a divisible parameter structure looks like and how it is equivalent to conjoint additivity.
A critical turning point in the mathematical history of measurement is the application of Jacob Bernoulli's 1713 binomial distribution as an inverse probability for interpreting the implications of observed events (Thomas Bayes, 1764, Pierre Laplace, 1774 in Stigler, 1986, pp. 63-67, 99-105). The data in hand are not what we seek. Our interests go beyond to what these data imply about other data yet unmet, but urgent to foresee. When we read our weight as 180 pounds, we take that number, not as a one-time, local description of a particular step onto this particular scale, but as our approximate "weight" right now, just before now, and, inferentially, for a useful time to come.
Inference
The first problem of inference is how to infer values for these other data,
which, by the meaning of "inference", are currently "missing". This includes the
data which are always missing in any actual attempt at data collection. Since
the purpose of inference is to estimate what future data might be like before we
encounter them, methods which require complete data in order to proceed cannot
by that very requirement be methods of inference. This realization engenders a
simple law:
Any statistical method nominated to serve inference which requires complete data, by this requirement, disqualifies itself as an inferential method.
But, if what we want to know is "missing", how can we use the data in hand to make useful inferences about the "missing" data they might imply? Inverse probability reconceives our raw observations as a probable consequence of a relevant stochastic process with a stable formulation. The apparent determinism of formulae like F = MA depends on the prior construction of relatively precise measures of M and A. The first step from raw observation to inference is to identify the stochastic process by which an inverse probability can be defined. Bernoulli's binomial distribution is the simplest and most widely used stochastic process. Its elaboration into the compound Poisson is the parent of all useful measuring distributions.
The second step to inference is to discover what mathematical models can govern the stochastic process in a way that enables a stable, ambiguity resilient estimation of the model's parameters from the limited data in hand. This step requires an awareness of the obstacles which stand in the way of stable inference.
At first glance, the second step to inference looks complicated. Its twentieth century history has followed so many paths, traveled by so many mathematicians that one might suppose there were no clear second step but only a jumble of unconnected possibilities along with their seemingly separate mathematical solutions. Fortunately, reflection on the motivations for these paths and examination of their mathematics leads to a reassuring simplification. Although each path was motivated by a particular concern as to what inference must overcome to succeed, all solutions end up with the same simple, easy to understand and easy to use formulation.
The second step to inference is solved by formulating the mathematical function which governs the inferential stochastic process so that its parameters are either infinitely divisible or conjointly additive i.e. separable. That's all there is to it!
Understanding what it takes to construct useful measures, however, has only
recently been applied in psychometric practice. This failure of practice has not
been due to lack of knowledge about the problems involved. Edward L. Thorndike,
the patriarch of educational measurement, observed in 1904 that:
If one attempts to measure even so simple a thing as spelling, one is hampered by the fact that there exist no units in which to measure. One may arbitrarily make up a list of words and observe ability by the number spelled correctly. But if one examines such a list one is struck by the inequality of the units. All results based on the equality of any one word with any other are necessarily inaccurate. (Thorndike, 1904, p.7)
Thorndike saw the unavoidable ambiguity in counting concrete events, however indicative they might seem. One might observe signs of spelling ability. But one would not have measured spelling, not yet (Engelhard, 1984, 1991, 1994). The problem of what to count, entity ambiguity, is ubiquitous in science, commerce and cooking. What is an "apple"? How many little apples make a big one? How many apples make a pie? Why don't three apples always cost the same amount? With apples, we solve entity ambiguity by renouncing the concrete apple count and turning, instead, to abstract apple volume or abstract apple weight (Wright, 1992, 1994).
Raw Scores are NOT measures
Unfortunately, in educational measurement, we have only recently begun to take this reasonable step from concrete counting to abstract measuring. Thorndike was not only aware of the "inequality of the units" counted but also of the non-linearity of any resulting "raw scores". Raw scores are limited to begin at "none right" and to end at "all right". But the linear measures we intend raw scores to imply have no such bounds. The monotonically increasing ogival exchange of one more right answer for a measure increment is steepest where items are dense, usually toward the middle of a test near 50% right. At the extremes of 0% and 100% right, however, the exchange becomes flat. This means that for a symmetrical set of item difficulties one more right answer implies the least measure increment near 50% but an infinite increment at each extreme.
The magnitude of this raw score bias against extreme measures depends on the distribution of item difficulties. The ratio of the measure increment corresponding to one more right answer at the next to largest extreme step with the measure increment corresponding to one more right answer at the smallest central step for a test with L normally distributed item difficulties is:
When items are heaped in the middle of a test, the usual case, then the bias for a 50 item test is 9 fold. Even when item difficulties are spread out uniformly in equal increments, the raw score bias against measure increments at the extremes for a 50 item test is 6 fold.
This raw score bias is not limited to dichotomous responses. The bias is just as severe for partial credits, rating scales and, of course, the infamous Likert Scale, the misuse of which pushed Thurstone's seminal 1920's work on how to transform concrete raw scores into abstract linear measures out of use.
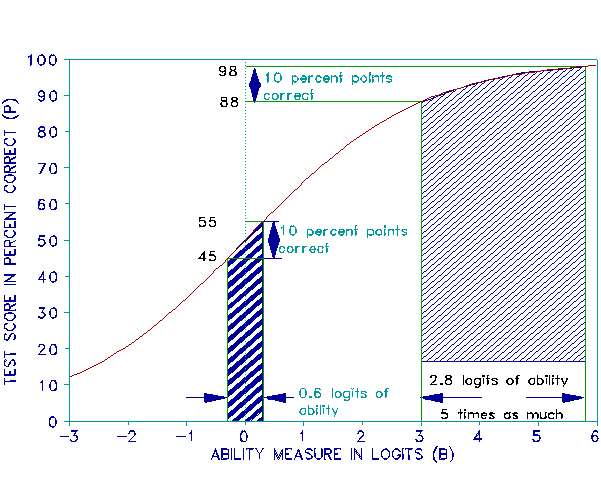
Figure 1 shows a typical raw score to measure ogive. Notice that the measure distance between scores of 88% and 98% is five times greater than the distance between scores of 45% and 55%.
The raw score bias in favor of central scores and against extreme scores, means
that raw scores are always targeting biased, as well as sample dependent (Wright
& Stone, 1979; Wright & Masters, 1982; Wright & Linacre, 1989). Any statistical
method like linear regression, analysis of variance, generalizability, or factor
analysis that uses raw scores or Likert scales as though they were linear
measures will have its output hopelessly distorted by this bias. That is why so
much social "science" has turned out to be no more than transient description of
never to be reencountered situations, easy to contradict with almost any
replication. The obvious and easy to practice (Wright & Linacre, 1997; Linacre
& Wright, 1997) law that follows is that:
Before applying linear statistical methods to concrete raw data, one must first use a measurement model to construct, from the observed raw data, abstract sample and test free linear measures.
There are two additional advantages obtained by model-controlled linearization. Each measure and each calibration is now accompanied by a realistic estimate of its precision and a mean square residual-from-expectation evaluation of the extent to which its data pattern fits the stochastic measurement model, i.e. its statistical validity. When we then move on to plotting results and applying linear statistics to analyze relationships among measures, we not only have linear measures to work with but we also know their numerical precision and numerical validity.
Fundamental Measurement
The general name for the kind of measurement we are looking for is "fundamental measurement". This terms comes from physicist Norman Campbell's 1920 deduction that the "fundamental" measurement (on which the success of physics was based) required, at least by analogy, the possibility of a physical concatenation, like joining the ends of sticks to concatenate length or piling bricks to concatenate weight. (Campbell, 1920)
Sufficiency
The estimator requirement to implement fundamental measurement is called
"sufficiency". In 1920 Ronald Fisher, while developing his "likelihood" version
of inverse probability to construct maximum likelihood estimation, discovered a
statistic so "sufficient" that it exhausted all information concerning its
modeled parameter from the data in hand (Fisher, 1920). Statistics which exhaust
all modelled information enable conditional formulations by which a value for
each parameter can be estimated independently of all other parameters in the
model. This follows because the presence of a parameter in the model can be
replaced by its sufficient statistic. Fisher's sufficiency enables independent
parameter estimation for models that incorporate many different parameters
(Andersen, 1977). This leads to another law:
When a psychometric model employs parameters for which there are no sufficient statistics, that model cannot construct useful measurement because it cannot estimate its parameters independently of one another.
Divisibility
What is the mathematical foundation for Campbell's "concatenation" and Fisher's "sufficiency"? In 1924 Paul Levy (1937) proved that the construction of laws which are stable with respect to arbitrary decisions as to what to count require infinitely divisible parameters. Levy's divisibility is logarithmically equivalent to the conjoint additivity (Luce & Tukey, 1964) which we now recognize as the mathematical generalization of Campbell's fundamental measurement. Levy's conclusions were reaffirmed in 1932 when A.N.Kolmogorov (1950, pp.9,57) proved that independence of parameter estimates also required divisibility, this time in the form of additive decomposition.
Thurstone
The problems for which "divisibility", and its consequences: concatenation and sufficiency, were the solution were not unknown to psychometricians. Between 1925 and 1932 electrical engineer and psychologist Louis Thurstone published 24 articles and a book on how to attempt solutions to these problems. Thurstone's requirements for useful measures are:
Unidimensionality:
The measurement of any object or entity describes only one attribute of the object measured. This is a universal characteristic of all measurement. (Thurstone, 1931, p.257)
Linearity:
The very idea of measurement implies a linear continuum of some sort such as length, price, volume, weight, age. When the idea of measurement is applied to scholastic achievement, for example, it is necessary to force the qualitative variations into a scholastic linear scale of some kind. (Thurstone & Chave, 1929, p.11)
Abstraction:
The linear continuum which is implied in all measurement is always an abstraction...There is a popular fallacy that a unit of measurement is a thing - such as a piece of yardstick. This is not so. A unit of measurement is always a process of some kind ...
Invariance:
... which can be repeated without modification in the different parts of the measurement continuum. (Thurstone 1931, p.257)
Sample free calibration:
The scale must transcend the group measured. A measuring instrument must not be seriously affected in its measuring function by the object of measurement...Within the range of objects...intended, its function must be independent of the object of measurement. (Thurstone, 1928, p.547)
Test free measurement:
It should be possible to omit several test questions at different levels of the scale without affecting the individual score (measure)... It should not be required to submit every subject to the whole range of the scale. The starting point and the terminal point...should not directly affect the individual score (measure). (Thurstone, 1926, p.446)
Thus by 1930 we had in print somewhere everything social science needed for the construction of stable, objective measures. The pieces were not joined. But, in the thinking of L.L. Thurstone, we knew exactly what was called for. And in the inverse probabilities of Bernoulli, Bayes and Laplace and the mathematics of Fisher, Levy and Kolmogorov we had what was missing from Thurstone's normal distribution method.
Guttman
Then in 1950 sociologist Louis Guttman pointed out that the meaning of any raw score, including Likert scales, would remain ambiguous unless the score specified every response in the pattern on which it was based.
If a person endorses a more extreme statement, he should endorse all less extreme statements if the statements are to be considered a scale...We shall call a set of items of common content a scale if a person with a higher rank than another person is just as high or higher on every item than the other person. (Guttman, 1950, p.62)
According to Guttman only data which form this kind of perfect conjoint transitivity can produce unambiguous measures. Notice that Guttman's definition of "scalability" is a deterministic version of Fisher's stochastic definition of "sufficiency". Each require that an unambiguous statistic must exhaust the information to which it refers.
Rasch
Complete solutions to Thurstone's and Guttman's requirements, however, did not emerge until 1953 when Danish mathematician, Georg Rasch (1960) deduced that the only way he could compare past performances on different tests of oral reading was to apply the exponential additivity of Poisson's 1837 distribution to data produced by a new sample of students responding simultaneously to both tests. Rasch used Poisson because it was the only distribution he could think of that enabled the equation of the two tests to be entirely independent of the obviously arbitrary distribution of the reading abilities of the new sample.
As Rasch worked out his mathematical solution to equating reading tests, he discovered that the mathematics of the probability process, the measurement model, must be restricted to formulations which produced sufficient statistics. Only when his parameters had sufficient statistics could he use these statistics to replace and hence remove the unwanted person parameters from his estimation equations and so obtain estimates of his test parameters which were independent of the incidental values or distributions of whatever other parameters were at work in the measurement model.
As Rasch describes the properties of his probability function, we see that he has constructed a stochastic solution to the impossibility of living up to Guttman's deterministic conjoint transitivity with raw data.
A person having a greater ability than another should have the greater probability of solving any item of the type in question, and similarly, one item being more difficult than another one means that for any person the probability of solving the second item correctly is the greater one. (Rasch, 1960, p.117)
Rasch completes his measurement model on pages 117-122 of his 1960 book. His "measuring function" on page 118 specifies the multiplicative definition of fundamental measurement for dichotomous observations as:
where P is the probability of a correct solution. f(P) is a function of P, still to be determined. b is a ratio measure of person ability. And d is a ratio calibration of item difficulty. This model applies the divisibility Levy requires for stability.
Rasch explains his measurement model as an inverse...
...probability of a correct solution, which may be taken as the imagined outcome of an indefinitely long series of trials...The formula says that in order that the concepts b and d could be at all considered meaningful, f(P), as derived in some way from P, should equal the ratio between b and d. (p.118, all italics are by Rasch)
And, after pointing out that a normal probit, even with its second parameter set to one, will be too "complicated" to serve as the measuring function f(P), Rasch asks: "Does there exist such a function, f(P), that f(P) = b/d is fulfilled? (p.119)
Because "an additive system...is simpler than the original...multiplicative system." Rasch takes logarithms:
which "for technical advantage" he expresses as the loge odds "logit":
The question has now reached its final form: "Does there exist a function g(L) of the variable L which forms an additive system in parameters for person B and parameters for items -D such that:
(pp.119-120)
Rasch then shows that the function g(L), which can be L itself, as in:
"contains all the possible measuring functions which can be constructed...by suitable choice of dimensions and units, A and C for:
Because of "the validity of a separability theorem (due to sufficiency):
It is possible to arrange the observational situation in such a way that from the responses of a number of persons to the set of items in question we may derive two sets of quantities, the distributions of which depend only on the item parameters, and only on the personal parameters, respectively. Furthermore the conditional distribution of the whole set of data for given values of the two sets of quantities does not depend on any of the parameters. (p.122)
With respect to separability the choice of this model has been lucky. Had we for instance assumed the "Normal-Ogive Model" with all si = 1 - which numerically may be hard to distinguish from the logistic - then the separability theorem would have broken down. And the same would, in fact, happen for any other conformity model which is not equivalent - in the sense of f(P) = C{f0(P)}A to f(P) = b/d...as regards separability. The possible distributions are...limited to rather simple types, but...lead to rather far reaching generalizations of the Poisson...process. (p.122)
By 1960 Rasch had proven that formulations in the compound Poisson family, such as Bernoulli's binomial, were not only sufficient but, more telling, also necessary for the construction of stable measurement. Rasch had found that the "multiplicative Poisson" was the only mathematical solution to the second step in inference, the formulation of an objective, sample and test free measurement model.
In 1992 Bookstein began reporting his astonishment at the mathematical equivalence of every counting law he could find. (Bookstein, 1992, 1996) In deciphering how this ubiquitous equivalence could occur, he discovered that the counting formulations were members of one family which was surprisingly robust with respect to ambiguities of entity (what to count), aggregation (what is countable) and scope (how long and how far to count). Bookstein discovered that the necessary and sufficient formulation for this remarkable robustness was Levy's divisibility and, as Rasch had seen 35 years earlier, that the one and only stochastic application of this requirement was the compound, i.e. multiplicative, Poisson distribution.
More recently Andrich (1978a, 1978b, 1978c), whose contributions in the 1970's made rating scale analysis practical and efficient, has shown that Rasch's separability requirement leads to the conclusion that the necessary and sufficient distribution for constructing measures from discrete observations is Poisson. (Andrich, 1995, 1996) The natural parameter for this Poisson is the ratio of the location of the object and the measurement unit of the instrument in question. This formulation preserves concatenation and divisibility and also the generality requirement that measurement in different units always implies the same location.
Conjoint Additivity
American work on mathematical foundations for measurement came to fruition with the proof by Duncan Luce and John Tukey (1964) that Campbell's concatenation was a physical realization of a general mathematical law which is "the" definition of fundamental measurement.
The essential character of...the fundamental measurement of extensive quantities is described by an axiomatization for the comparison of effects of arbitrary combinations of "quantities" of a single specified kind...Measurement on a ratio scale follows from such axioms.
The essential character of simultaneous conjoint measurement is described by an axiomatization for the comparison of effects of pairs formed from two specified kinds of "quantities"... Measurement on interval scales which have a common unit follows from these axioms.
A close relation exists between conjoint measurement and the establishment of response measures in a two-way table ...for which the "effects of columns" and the "effects of rows" are additive. Indeed the discovery of such measures...may be viewed as the discovery, via conjoint measurement, of fundamental measures of the row and column variables. (Luce & Tukey, 1964, p.1)
In spite of the practical advantages of such response measures, objections have been raised to their quest...The axioms of simultaneous conjoint measurement overcome these objections...Additivity is just as axiomatizable as concatenation...in terms of axioms that lead to ... interval and ratio scales.
In... the behavioral and biological sciences, where factors producing orderable effects and responses deserve more useful and more fundamental measurement, the moral seems clear: when no natural concatenation operation exists, one should try to discover a way to measure factors and responses such the "effects" of different factors are additive. (Luce & Tukey, 1964, p.4)
Although conjoint additivity has been known to be a decisive requirement for fundamental measurement since 1964, few social scientists realize that Rasch models are its fully practical realization (Wright, 1984). Rasch models construct conjoint additivity by applying inverse probability to empirical data and then test these data for their goodness-of-fit to this measurement construction (Keats, 1967, Fischer, 1968; Wright,1968; Perline, Wright, Wainer, 1978).
The Rasch model is a special case of additive conjoint measurement... a fit of the Rasch model implies that the cancellation axiom (i.e. conjoint transitivity) will be satisfied...It then follows that items and persons are measured on an interval scale with a common unit. (Brogden, 1977, p.633)
We can summarize the history of inference in a table according to four obstacles which stand between raw data and the stable inference of measures they might imply.
| OBSTACLES | SOLUTIONS | INVENTORS |
| UNCERTAINTY have -> want now -> later statistic -> parameter |
PROBABILITY binomial odds regular irregularity misfit detection |
Bernoulli 1713 Bayes 1764 Laplace 1774 Poisson 1837 |
| DISTORTION non-linearity unequal intervals incommensurability |
ADDITIVITY linearity concatenation conjoint additivity |
Fechner 1860 Helmholtz 1887 N.Campbell 1920 Luce/Tukey 1964 |
| CONFUSION interdependence interaction confounding |
SEPARABILITY sufficiency invariance conjoint order |
Rasch 1958 R.A.Fisher 1920 Thurstone 1925 Guttman 1944 |
| AMBIGUITY of entity, interval and aggregation |
DIVISIBILITY independence stability reproducibility exchangeability |
Levy 1924 Kolmogorov 1932 Bookstein 1992 de Finetti 1931 |
Uncertainty is the motivation for inference. The future is uncertain by definition. We have only the past by which to foresee. Our solution is to capture uncertainty in a construction of imaginary probability distributions which regularize the irregularities that disrupt connections between what seems certain now but is uncertain later. The solution to uncertainty is Bernoulli's inverse probability.
Distortion interferes with the transition from observation to conceptualization. Our ability to figure things out comes from our faculty to visualize. Our power of visualization evolved from the survival value of body navigation through the three dimensional space in which we live. Our antidote to distortion is to represent our observations of experience in the linear form that makes them look like the space in front of us. To "see" what experience "means", we "map" it.
Confusion is caused by interdependencies. As we look for tomorrow's probabilities in yesterday's lessons, confusing interactions intrude. Our resolution of confusion is to represent the complexity we experience in terms of a few shrewdly invented "dimensions". The authority of these dimensions is their utility. Final "Truths" are unknowable. But, when our inventions work, we find them "useful". And when they continue to work, we come to count on them and to call them "real" and "true".
The method we use to control confusion is to enforce our ideas of unidimensionality. We define and measure one invented dimension at a time. The necessary mathematics is parameter separability. Models which introduce putative "causes" as separately estimable parameters are our laws of quantification. These models define measurement, determine what is measurable, decide which data are useful and expose data which are not.
Ambiguity, a fourth obstacle to inference, occurs because there is no non-arbitrary way to determine exactly which particular definitions of existential entities are the "right" ones to count. As a result the only measurement models that can work are models that are indifferent to level of composition. Bookstein (1992) shows that to accomplish this the models must embody parameter divisibility or additivity as in:
Fortunately the mathematical solutions to Ambiguity, Confusion and Distortion are identical. The parameters in the model governing the probability of the data must appear in either a divisible or additive form. Following Bookstein enables:
1. The conjoint additivity which Norman Campbell (1920) and Luce and Tukey (1964) require for fundamental measurement and which Rasch's models provide in practice (Perline, Wright & Wainer, 1979; Wright, 1985, 1988).
2. The exponential linearity which Ronald Fisher (1920) requires for estimation sufficiency (Andersen, 1977; Wright, 1989).
3. The parameter separability which Louis Thurstone (1925) and Rasch (1960) require for objectivity (Wright & Linacre, 1988).
No model which fails to satisfy the four necessities for inference: probability, additivity, separability and divisibility, can survive actual practice. No other formulation can define or construct results which any scientist, engineer, business man, tailor or cook would be willing to use as measures. Only data which can be understood and organized to fit such a model can be useful for constructing measures. When data cannot be made to fit such a model, the inevitable conclusion will be that those data are inadequate and must be reconsidered, perhaps omitted, perhaps replaced. (Wright, 1977)
Turning to the details of practice, our data comes to us in the form of nominal response categories like:
yes/no
right/wrong
present/absent
always/usually/sometimes/never
strongly agree/agree/disagree/strongly disagree
and so on.
The labels we choose for these categories suggest an ordering from less to more: more "yes", more "right" more "present", more "frequent", more "agreeable". Without thinking much about it we take as linguistically given a putative hierarchy of ordinal response categories, an ordered rating scale. But whether responses to these labels are, in practice, actually distinct or even ordered remains to be discovered when we try to use our data to construct useful measures.
It is not only the unavoidable ambiguity of what is counted nor our lack of knowledge as to the functioning distances between the ordered categories that mislead us. The response counts cannot form a linear scale. Not only are they restricted to occur as integers between none and all. Not only are they systematically biased against off target measures. But, because, at best, they are counts, their natural quantitative comparison will be as ratios rather than differences. Means and standard deviations calculated from these ranks are systematically misleading.
There are serious problems in our initial raw data: ambiguity of entity, non-linearity and confusion of source (Is it the smart person or the easy item that produces the "right" answer?). In addition it is not these particular data which interest us. Our needs focus on what these local data imply about more extensive, future data which, in the service of inference, are by definition "missing". We therefore apply the inverse probability step to inference by addressing each piece of observed data, xni, as a stochastic consequence of a modeled probability of occurring, Pnix. Then we take the mathematical step to inference by connecting Pnix to a conjointly additive function which specifies how the measurement parameters in which we are interested are supposed to govern Pnix.
Our parameters could be Bn the location measure of person n on the continuum of reference, Di the location calibration of item i on the same continuum and Fx the threshold of the transition from category (x-1) to category (x). The necessary and sufficient formulation is:
in which the symbol "==" means "by definition" rather than merely "equals".
On the left of this measurement model we see the replacement of xni by its Bernoulli/Bayes/Laplace stochastic proxy Pnix. On the right we see the Campbell/Luce/Tukey conjoint additivity which produces parameter estimates in the linear form to which our eyes, hands and feet are so accustomed.
Exponentiating shows how this model also meets the Levy/Kolmogorov/Bookstein divisibility requirement. But it is the linear form which serves our scientific aims best. When we want to see what we mean, we draw a picture because only seeing is believing. But the only pictures we see clearly are maps of linear measures. Graphs of ratios mislead us. Try as we might, our eyes cannot "see" things that way. Needless to say, what we cannot "see" we cannot understand, let alone believe.
Indeed, Fechner (1860) showed that when we experience any kind of ratio -light, sound or pain - our nervous system "takes its logarithm" so that we can "see how it feels" on a linear scale. Nor was Fechner the first to notice this neurological phenomena. In the Pythagorean scale musical instruments sound out of tune at each change of key. Tuning is key-dependent. This problem was solved in the 17th century by tuning instruments, instead, to notes which increased in frequency by equal ratios. Equal ratio tuning produced an "equally tempered" scale of notes which sound equally spaced in any key. Bach wrote "The Well-Tempered Clavier" to demonstrate the validity of this invention.
These conclusions, so thoroughly founded on the seminal work of great mathematicians, have penetrating consequences. This history teaches us not only what to do but also what NOT to do. No study of history is complete without learning from the wrong directions and blind alleys by which we were confused and mislead. What, then, are the unlearned lessons in the history of social science measurement? Several significant blind alleys stand out.
Do NOT Use Raw Scores As Though They Were Measures
Many social scientists still believe that misusing raw scores as measures does no harm. They are unaware of the consequences for their work of the raw score bias against extreme scores. Some believe that they can construct measures by decomposing raw score matrices with some kind of factor analysis. There is a similarity between measurement construction and factor analysis in the way that they expose multi-dimensionality. (Smith, 1996) But factor analysis does not construct measures (Wright, 1996) All results from raw score analyses are spoiled by their non-linearity, their extreme score bias and their sample dependence.
Do NOT Use Non-Additive Models
Among those who have seen their way beyond raw scores to "Item Response Theory" [IRT] there is a baffling misunderstanding concerning the necessity for conjoint additivity and sufficient statistics. These adventurers cannot resist trying their luck with measurement models like:
which they call the "2P" and "3P" IRT models of Birnbaum (Lord & Novick, 1968). These models are imagined to be improvements over the "1P Rasch model" because they include an item scaling parameter Ai to estimate a "discrimination" for each item and a lower asymptote parameter Ci to estimate a "guessing" level for each item. But, because these extra parameters are not additive, their proponents find, when the try to apply them to data, that:
Item discriminations "increase without limit." Person abilities "increase or decrease without limit." (Lord, 1968, pp.1015-1016)
Even for data generated to fit the 3PL (3-PL, three parameter logistic model) model exactly, "only item difficulty is satisfactorily recovered by [the 3P computer program] LOGIST." (Lord, 1975 p.13) "If restraints are not imposed, the estimated value of discrimination is likely to increase without limit." (Lord, 1975 p.14) "Left to itself, maximum likelihood estimation procedures would produce unacceptable values of guessing." (Lord, 1975 p.16)
During "estimation in the two and three parameter models...the item parameter estimates drift out of bounds." (Swaminathan, 1983, p.34)
"Range restrictions (must be) applied to all parameters except the item difficulties" to control "the problem of item discrimination going to infinity." (Wingersky, 1983, p.48)
"Bias [in person measures] is significant when ability estimates are obtained from estimated item parameters...And, in spite of the fact that the calibration and cross-validation samples are the same for each setting, the bias differs by test." (Stocking, 1989, p.18)
"Running LOGIST to complete convergence allows too much movement away from the good starting values." (Stocking, 1989, p.25)."
The reason why 2P and 3P IRT models do not converge is clear in Birnbaum's original (Lord & Novick, 1968 pp.421-422) estimation equations:
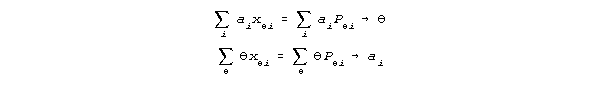
These equations are intended to iterate reciprocally to convergence. When the first equation is applied to a person with a correct response xi = 1 on an item with discrimination ai > 1, their ability estimate is increased by the factor ai. When the second equation is applied, the same person response xi = 1 is multiplied by their increased ability estimate which further increases discrimination estimate ai. The presence of response xi = 1 on both sides of these reciprocal equations produces a feedback which soon escalates the estimates for item discrimination ai and person measure to infinity.
Do NOT Use Models that Fail to Minimize Residuals
The sine qua non of a statistical model is its success at reproducing its data. The simplest evaluation of success is the mean square residual between each piece of data x and its modeled expectation Ex, as in the mean of (x - Ex)2 over x. Ordinarily, the more parameters a model uses, the smaller the mean square residual becomes. Otherwise why add more parameters. Should we ever encounter a parameter the addition of which increases our mean square residuals, we have exposed a parameter that works against the intentions of our model.
Hambleton and Martois used LOGIST to analyze 18 sets of data twice, first with a 1 item parameter Rasch model and second with a 3 item parameter Birnbaum model (Hambleton & Martois, 1983). In 12 of their 18 experiments, much to their surprise, two less item parameters, i.e. the Rasch model, produced smaller mean square residuals than their 3 item parameter model. In the six data sets where this did not happen, the tests were unusually difficult for the students. As a result, attempting to estimate "guessing" parameters reduced residuals slightly more than the Rasch model without a guessing constant.
Had a single a priori guessing constant been set at a reasonable value like C = .25 for all items and the data reanalyzed with a 1P Rasch model so modified, Hambleton and Martois would have discovered that one well-chosen apriori guessing constant did a better job than attempting to estimate a full set of item specific guessing parameters. When we encounter a situation in which the addition of a parameter makes things worse, we have proven to ourselves that the parameter in question does not belong in our model.
Do NOT Destroy Additivity
Another way to see the problem is to attempt to separate parameters for independent estimation by subtraction. Using Gni as the data-capturing loge odds side of the model for a dichotomy, consider the following Rasch equations:
when Gni = Bn - DiGmi = Bm - DiGnj = Bn - Dj
then Gni - Gmi = Bn - Bm
so that Di drops out of consideration.
and Gni - Gnj = Dj - Di
so that Bn drops out of consideration.
Now consider the parallel 2P model equations:
when Gni = Ai(Bn - Di)Gmi = Ai(Bm - Di)Gnj = Aj(Bn - Dj)
then Gni - Gmi = Ai(Bm - Bn)
and we are stuck with Ai
and Gni - Gnj = Bn(Ai - Aj) + AiDi - AjDj
and we are stuck with Bn
We cannot separate these parameters in order to estimate them independently.
But Merely Asserting Additivity is NOT Enough
Parameters can be combined additively and asserted to govern a monotonic probability function over an infinite range, yet fail to construct stable fundamental measurement. Consider Goldstein (1980):
and Samejima (1997):
two models which appear to specify conjoint additivity, but do not construct fundamental measurement.
Not only does neither model provide sufficient statistics for B and D, but both models fail to construct unique measures. To see this, reverse the direction of the latent variable and focus on person deficiency (-Bn), item easiness (-Di) and task failure (1-Pni).
Rasch (1960):
becomes
in which nothing changes but direction.
Goldstein (1980):
however,
becomes
which does NOT equal -loge[-loge(Pni)] unless [logPni][loge(1-Pni)] = 1
and
Samejima (1997):
becomes
which does NOT equal -{{loge[Pni/(1-Pni)]}-A} unless A=1
which makes Samejima's model the Rasch model.
For Goldstein and Samejima, merely measuring from the other end of the ruler produces a second set of measures which are incommensurable with the first. The mere assertion of additivity on one side of a model is not enough. To produce fundamental measurement, the model must reproduce itself regardless of direction.
Do NOT Destroy Construct Stability
Finally there is a fundamental illogic in attempting to define a construct with item characteristic curves [ICC] which are designed to cross by letting their slopes differ due to differing item discriminations or their asymptotes differ due to differing item guessing parameters. The resulting crossing curves destroy the variable's criterion definition because the hierarchy of relative item difficulty to becomes different at every level of ability.

Figure 2 shows the relative locations of Rasch item calibrations for five words drawn from the word recognition construct Woodcock defined with Rasch item calibrations (Woodcock, 1974). Notice that it does not matter whether the level of ability is at 1st, 2nd or 3rd Grade, the words "red", "away", "drink", "octopus" and "equestrian" remain in the same order of experienced difficulty, at the same relative spacing. This word recognition ruler works the same way and defines the same variable for every child whatever their grade. It obeys the Magna Carta.
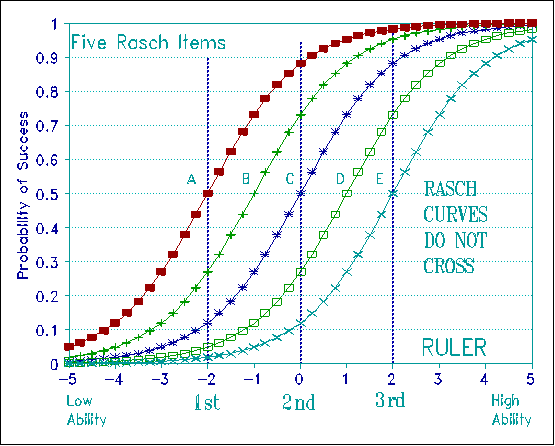
To obtain the construct stability evident in Figure 2 we need the kind of item response curves which follow from the standard definition of fundamental measurement. Figure 3 shows that these Rasch curves do not cross. When we transform the vertical axis of these curves into log-odds instead of probabilities, the curves become parallel straight lines, thus demonstrating their conjoint additivity.
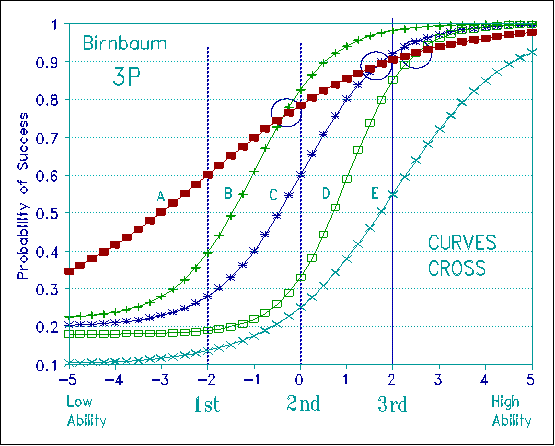
Figure 4, in contrast, shows five 3P Birnbaum curves for the same data. These five curves have different slopes and different asymptotes. There is no sign of conjoint additivity.
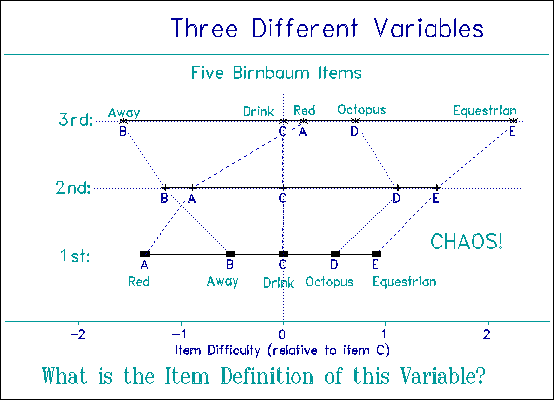
Figure 5 shows the construct destruction produced by the crossing curves of Figure 4. Now for a 1st Grader, "red" is calibrated to be easier than "away" which is easier than "drink" which is easier than "octopus". But for a 3rd Grader the order of item difficulty is different. Now it is "away" rather than "red" that is easier. "Red" has become harder than "drink"! And "octopus" is nearly as easy to recognize as "red", instead of being nearly as hard as "equestrian". What is the criterion definition of this variable? What construct is defined? The definition is different at every level of ability. There is no construct! No ruler! No Magna Carta!
Much as we might be intrigued by the complexity of the Birnbaum 3P curves in Figure 4, we cannot use them to construct measures. To construct measures we require orderly, cooperating, non-crossing curves like the Rasch curves in Figure 3. This means that we must take the trouble to collect and refine data so that they serve this clearly defined purpose, so that they approximate a stochastic Guttman scale.
When we go to market, we eschew rotten fruit. When we make a salad, we demand fresh lettuce. We have a recipe for what we want. We select our ingredients to follow. It is the same with making measures. We must think ahead when we select and prepare our data for analysis. It is foolish to swallow whatever comes. Our data must be directed to building a structure like the one in Figures 2 and 3 -- one ruler for everyone, everywhere, every time - so we can achieve a useful, stable construct definition like Woodcock's word-recognition ruler.
There is a vast difference between gerrymandering whatever kind of "model" might seem to give a locally "good" description of some transient set of data and searching, instead, for the kind of data that can yield inferentially stable, i.e. generalizable, meaning to the parameter estimates of interest. The 3P model is data driven: The model must fit, else find another model. It seldom objects to an item, no matter how badly it functions. The Rasch model is theory driven: The data must fit, else find better data. Indeed, it is the search for better data which sets the stage for discovery. The only way discovery can occur is as an unexpected discrepancy from an otherwise stable frame of reference. When we study data misfit to the Rasch model we discover new things about the nature of what we are measuring and the way that people are able to tell us about it in their responses. These discoveries are important events which strengthen and clarify our construct as well as our ability to measure it.
We have recalled the political and moral history of stable units for fair taxation and trade. When units are unequal, when they vary from time to time and place to place, it is not only unfair. It is immoral. So too with the misuse of necessarily unequal and so unfair raw score units.
The purpose of measurement is inference. We measure to inform and specify our plans for what to do next. If our measures are unreliable, if our units vary in unknown ways, our plans must go astray. This might seem a small point. Indeed, it has been belittled by presumably knowledgeable social scientists. But, far from being small, it is a vital and decisive! We will never build a useful, let along moral, social science until we stop deluding ourselves by analyzing raw scores as though they were measures (Wright, 1984).
Laws of Measurement
Some laws which are basic to the construction of measurement have emerged:
Any statistical method nominated to serve inference which requires complete data, by this very requirement, disqualifies itself as an inferential method.
When a model employs parameters for which there are no sufficient statistics, that model cannot construct useful measurement because it cannot estimate its parameters independently of one another.
Before applying linear statistical methods to raw data, one must first use a measurement model to construct [not merely assert] from the raw data observed, coherent sample and test free linear measures.
Requirements for Measures
The history of measurement can be summarized as the history of the way in which solutions to Thurstones' requirements:
1. Measures must be linear, so that arithmetic can be done with them.
2. Item calibrations must not depend on whose responses are used to estimate them - must be sample free.
3. Person measures must not depend on which items they happened to take - must be test free.
4. Missing data must not matter.
5. The method must be easy to apply.
were latent in Campbell's 1920 concatenation, Fisher's 1920 sufficiency and the divisibility of Levy and Kolmogorov, clarified by Guttman's 1950 conjoint transitivity and realized by Rasch's 1953 additive Poisson model.
Guessing and Discrimination
The history of Birnbaum's 3P model is a cautionary tale. Guessing is celebrated as a reliable item asset. Discrimination is saluted as a useful scoring weight. Crossed item characteristic curves are shrugged off as naturally unavoidable. The Rasch model is more choosy. It recognizes guessing, not as an item asset but, as an unreliable person liability. Variation in discrimination, a sure symptom of item bias and multi-dimensionality, is also rejected (Masters, 1988). Unlike the Birnbaum model, the Rasch model does not parameterize discrimination and guessing and then forget them. The Rasch model always analyzes the data for statistical symptoms of variation in discrimination and guessing, identifies their sources and weighs their impact on measurement quality (Smith, 1985, 1986, 1988, 1991, 1994).
In practice, guessing is easy to minimize by using well-targeted tests. When it does occur, it is not items that do the guessing. The place to look for guessing is among guessers. Even then, few people guess. But, from time to time, some people do seem to have scored a few lucky guesses. The most efficient and most fair way to deal with guessing, when it does occur, is to detect it and then to decide what is the most reasonable thing to do with the improbably successful responses the lucky guesser may have chanced upon.
Fundamental Measurement
The knowledge needed to construct fundamental measures from raw scores has been with us for 40 years. Despite hesitation by some to use fundamental measurement models to transform raw scores into measures so that subsequent statistical analysis can become fruitful, there have been many successful applications (Wilson, 1992, 1994; Fisher & Wright, 1994; Engelhard & Wilson, 1996; Smith, 1997, Wilson & Engelhard, 1997).
Rasch's model is being extended to address every imaginable raw observation: dichotomies, rating scales, partial credits, binomial and Poisson counts (Masters & Wright, 1984) in every reasonable observational situation including ratings faceted to: persons, items, judges and tasks (Linacre, 1989).
Computer programs which apply Rasch models have been in circulation for 30 years (Wright & Panchapakesan, 1969). Convenient and easy to use software to accomplish the application of Rasch's "measuring functions" is readily available (Wright & Linacre, 1997; Linacre & Wright, 1997).
Today it is easy for any scientist to use these computer programs to traverse the decisive step from their unavoidably ambiguous concrete raw observations to well-defined abstract linear measures with realistic precision and validity estimates. Today there is no methodological reason why social science cannot become as stable, as reproducible and hence as useful as physics.
Benjamin D. Wright MESA Psychometric Laboratory
Andersen, E.B. (1977). Sufficient statistics and latent trait models. Psychometrika, (42), 69-81.
Andrich, D. (1978a). A rating formulation for ordered response categories. Psychometrika, (43), 561-573.
Andrich, D. (1978b). Scaling attitude items constructed and scored in the Likert tradition. Educational and Psychological Measurement,(38), 665-680.
Andrich, D. (1978c). Application of a psychometric rating model to ordered categories which are scored with successive integers. Applied Psychological Measurement,(2), 581-594.
Andrich, D. (1995). Models for measurement: precision and the non-dichotomization of graded responses. Psychometrika, (60), 7-26.
Andrich, D. (1996). Measurement criteria for choosing among models for graded responses. In A.von Eye and C.C.Clogg (Eds.), Analysis of Categorical Variable in Developmental Research. Orlando: Academic Press. 3-35.
Bookstein, A. (1992). Informetric Distributions, Parts I and II. Journal of the American Society for Information Science, 41(5):368-88.
Bookstein, A. (1996). Informetric Distributions. III. Ambiguity and Randomness. Journal of the American Society for Information Science, 48(1): 2-10.
Brogden, H.E. (1977). The Rasch model, the law of comparative judgement and additive conjoint measurement. Psychometrika, (42), 631-634.
Campbell, N.R. (1920). Physics: The elements. London: Cambridge University Press.
de Finetti, B. (1931). Funzione caratteristica di un fenomeno aleatorio. Atti dell R. Academia Nazionale dei Lincei, Serie 6. Memorie, Classe di Scienze Fisiche, Mathematice e Naturale, 4, 251-99. [added 2005, courtesy of George Karabatsos]
Engelhard, G. (1984). Thorndike, Thurstone and Rasch: A comparison of their methods of scaling psychological tests. Applied Psychological Measurement, (8), 21-38.
Engelhard, G. (1991). Thorndike, Thurstone and Rasch: A comparison of their approaches to item-invariant measurement. Journal of Research and Development in Education, (24-2), 45-60.
Engelhard, G. (1994). Historical views of the concept of invariance in measurement theory. In Wilson, M. (Ed), Objective Measurement: Theory into Practice, Volume 2. Norwood, N.J.: Ablex, 73-99.
Engelhard, G. & Wilson, M. (Eds) (1996). Objective Measurement: Theory into Practice Volume 3. Norwood, N.J.: Ablex
Fechner, G.T. (1860). Elemente der psychophysik. Leipzig: Breitkopf & Hartel. [Translation: Adler, H.E. (1966). Elements of Psychophysics. New York: Holt, Rinehart & Winston.].
Feller, W. (1950). An introduction to probability theory and its applications, Volume I. New York: John Wiley.
Fischer, G. (1968). Psychologische Testtheorie. Bern: Huber.
Fisher, R.A. (1920). A mathematical examination of the methods of determining the accuracy of an observation by the mean error and by the mean square error. Monthly Notices of the Royal Astronomical Society,(53),758-770.
Fisher, W.P. & Wright, B.D. (1994). Applications of Probabilistic Conjoint Measurement. Special Issue. International Journal Educational Research, (21), 557-664.
Goldstein, H. (1980). Dimensionality, bias, independence and measurement scale problems in latent trait test score models. British Journal of Mathematical and Statistical Psychology, (33), 234-246.
Guttman, L. (1950). The basis for scalogram analysis. In Stouffer et al. Measurement and Prediction, Volume 4. Princeton N.J.: Princeton University Press, 60-90.
Hambleton, R. & Martois, J. (1983). Test score prediction system. In Applications of item response theory. Vancouver, BC: Educational Research Institute of British Columbia, 208-209.
Keats, J.A. (1967). Test theory. Annual Review of Psychology, (18), 217-238.
Kolmogorov, A.N. (1950). Foundations of the Theory of Probability. New York: Chelsea Publishing.
Levy, P. (1937). Theorie de l'addition des variables aleatoires. Paris.
Linacre, J.M. (1989). Many-faceted Rasch Measurement. Chicago: MESA Press.
Linacre, J.M. & Wright, B.D. (1997). FACETS: Many-Faceted Rasch Analysis. Chicago: MESA Press.
Lord, F.M. (1968). An analysis of the Verbal Scholastic Aptitude Test Using Birnbaum's Three-Parameter Model. Educational and Psychological Measurement, 28, 989-1020.
Lord, F.M. (1975). Evaluation with artificial data of a procedure for estimating ability and item characteristic curve parameters. (Research Report RB-75-33). Princeton: ETS.
Lord, F.M. & Novick M.R. (1968) Statistical Theories of Mental Test Scores. Reading, Mass: Addison-Wesley.
Luce, R.D. & Tukey, J.W. (1964). Simultaneous conjoint measurement. Journal of Mathematical Psychology,(1),1-27.
Master, G.N. (1988). Item discrimination: When more is worse. Journal of Educational Measurement, (24), 15-29.
Masters, G.N. & Wright, B.D. (1984). The essential process in a family of measurement models. Psychometrika, (49), 529-544.
Perline, R., Wright, B.D. & Wainer, H. (1979). The Rasch model as additive conjoint measurement. Applied Psychological Measurement, (3), 237-255.
Rasch, G. (1960). Probabilistic models for some intelligence and attainment tests. [Danish Institute of Educational Research 1960, University of Chicago Press 1980, MESA Press 1993] Chicago: MESA Press.
Samejima, F. (1997). Ability estimates that order individuals with consistent philosophies. Annual Meeting of the American Educational Research Association. Chicago: AERA.
Sears, S.D. (1997). A Monetary History of Iraq and Iran. Ph.D. Dissertation. Chicago: University of Chicago.
Smith, R.M. (1985). Validation of individual test response patterns. International Encyclopedia of Education, Oxford: Pergamon Press, 5410-5413.
Smith, R.M. (1986). Person fit in the Rasch Model. Educational and Psychological Measurement, (46), 359-372.
Smith, R.M. (1988). The distributional properties of Rasch standardized residuals. Educational and Psychological Measurement, (48), 657-667.
Smith, R.M. (1991). The distributional properties of Rasch item fit statistics. Educational and Psychological Measurement, (51), 541-565.
Smith, R.M. (1994). A comparison of the power of Rasch total and between item fit statistics to detect measurement disturbances. Educational and Psychological Measurement, (54), 42-55.
Smith, R.M. (1996). A comparison of methods for determining dimensionality. Structural Equation Modeling, 3(1), 25-40.
Smith, R.M. (Ed), (1997). Outcome Measurement. Physical Medicie and Rehabilitation: State of the Art Reviews, 11(2). Philadelphia: Hanley & Belfus.
Stigler, S.M. (1986). The History of Statistics. Cambridge: Harvard University Press.
Stocking, M.L. (1989). Empirical estimation errors in item response theory as a function of test properties. (Research Report RR-89-5). Princeton: ETS.
Thorndike, E.L. (1904). An introduction to the theory of mental and social measurements. New York: Teacher's College.
Thurstone, L.L. (1925). A method of scaling psychological and educational tests. Journal of Educational Psychology,(16), 433-451.
Thurstone, L.L. (1926). The scoring of individual performance. Journal of Educational Psychology, (17), 446-457.
Thurstone, L.L. (1928). Attitudes can be measured. American Journal of Sociology, (23), 529-554.
Thurstone, L.L. (1931). Measurement of social attitudes. Journal of Abnormal and Social Psychology, (26), 249-269.
Thurstone, L.L. & Chave, E.J. (1929). The measurement of attitude. Chicago: University of Chicago Press.
Wilson, M. (Ed) (1992). Objective Measurement: Theory into Practice Volume 1. Norwood, N.J.: Ablex.
Wilson, M. (Ed) (1994). Objective Measurement: Theory into Practice Volume 2. Norwood, N.J.: Ablex.
Wilson, M., Engelhard, G. & Draney, K. (Eds) (1997). Objective Measurement: Theory into Practice Volume 4. Norwood, N.J.: Ablex.
Woodcock, R.W. (1974). Woodcock Reading Mastery Tests. Circle Pines, Minn: American Guidance Service.
Wright, B.D. (1968). Sample-free test calibration and person measurement. Proceedings 1967 Invitational Conference on Testing Princeton: Educational Testing Service, 85-101.
Wright, B.D. (1977). Solving measurement problems with the Rasch model. Journal of Educational Measurement, (14), 97-116.
Wright, B.D. (1984). Despair and hope for educational measurement. Contemporary Education Review, (1), 281-288.
Wright, B.D. (1985). Additivity in psychological measurement. In Edw. Roskam, Measurement and Personality Assessment. Amsterdam: North-Holland, 101-112.
Wright, B.D. (1988). Rasch model from Campbell concatenation for mental testing. Reprinted in Linacre, J.M. (Ed), Rasch Measurement Transactions Part 1. Chicago: MESA Press, 1995, 16.
Wright, B.D. (1989). Rasch model from counting right answers. Reprinted in Linacre, J.M. (Ed), Rasch Measurement Transactions Part 1. Chicago: MESA Press, 1995, 62.
Wright, B.D. (1992). IRT in the 1990's: Which models work best?.
Reprinted in Linacre, J.M. (Ed), Rasch Measurement Transactions Part 2. Chicago: MESA Press, 1996, 196-200.
Wright, B.D. (1994). Measuring and counting. Reprinted in Linacre, J.M. (Ed), Rasch Measurement Transactions Part 2. Chicago: MESA Press, 1996, 371.
Wright, B.D. (1996). Comparing Rasch measurement and factor analysis. Structural Equation Modeling, 3(1), 3-24.
Wright, B.D. & Linacre, J.M. (1988). Reprinted in Linacre, J.M. (Ed), Rasch Measurement Transactions Part 1. Chicago: MESA Press, 1995, 5-6.
Wright, B.D. & Linacre, J.M. (1989). Observations are always ordinal: measures, however, must be interval. Archives of Physical Medicine and Rehabilitation, (70), 857-860.
Wright, B.D. & Linacre, J.M. (1997). BIGSTEPS: Rasch Computer Program for All Two Facet Problems. Chicago: MESA Press.
Wright, B.D. & Masters, G.N. (1982). Rating Scale Analysis: Rasch Measurement. Chicago: MESA Press.
Wright, B.D. & Panchapakesan, N. (1969). A procedure for sample-free item analysis. Educational and Psychological Measurement, (29), 23-48.
Wright, B.D. & Stone, M.H. (1979). Best Test Design: Rasch Measurement. Chicago: MESA Press.
Go to Top of Page
Go to Institute for Objective Measurement Page
| FORUM | Rasch Measurement Forum to discuss any Rasch-related topic |
| Coming Rasch-related Events | |
|---|---|
| Apr. 21 - 22, 2025, Mon.-Tue. | International Objective Measurement Workshop (IOMW) - Boulder, CO, www.iomw.net |
| Jan. 17 - Feb. 21, 2025, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
| Feb. - June, 2025 | On-line course: Introduction to Classical Test and Rasch Measurement Theories (D. Andrich, I. Marais, RUMM2030), University of Western Australia |
| Feb. - June, 2025 | On-line course: Advanced Course in Rasch Measurement Theory (D. Andrich, I. Marais, RUMM2030), University of Western Australia |
| May 16 - June 20, 2025, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
| June 20 - July 18, 2025, Fri.-Fri. | On-line workshop: Rasch Measurement - Further Topics (E. Smith, Facets), www.statistics.com |
| July 21 - 23, 2025, Mon.-Wed. | Pacific Rim Objective Measurement Symposium (PROMS) 2025, www.proms2025.com |
| Oct. 3 - Nov. 7, 2025, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
Our current URL is www.rasch.org
The URL of this page is www.rasch.org/memo62.htm